Prometheus
CNCF에서 관리하는 오픈소스 모니터링 및 알람 시스템입니다.
Prometheus는 이러한 문제를 해결하기 위해 시계열 데이터(time-series data) 수집 및 저장에 최적화된 구조를 갖추고 있으며, 쿼리 언어(PromQL)를 통해 데이터를 분석하고, 알람을 설정할 수 있습니다.
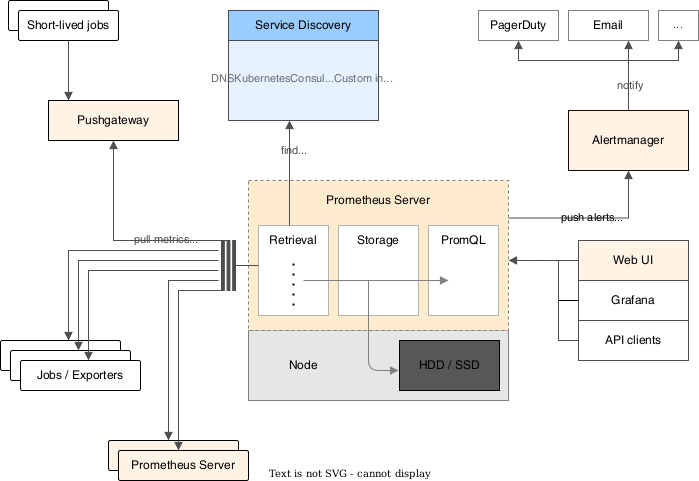
Prometheus의 구성요소
1) Prometheus operator
쿠버네티스 환경에서 Prometheus의 배포와 관리를 자동화하는 도구, 설치부터 설정관리까지 CRD로 관리합니다.
- Custom Resource 정의 및 관리
- Podmonitor, Servicemonitor 등 CRD 정의하여 쿠버네티스 내에서 관리
- 자동 설정 및 업데이트
- 관리하는 리소스의 변경을 감자항 Prometheus 스크래핑 대상 설정을 자동으로 업데이트
2) Prometheus Server
설정된 scrape_configs에 따라 메트릭을 주기적으로 수집 및 저장합니다. (TSDB 사용)
- exporter로 부터 메트릭 읽어와서 수집 (pull 방식)
- 메트릭을 TSDB에 저장
- PromQL을 통해 데이터 조회
3) Exporter
Prometheus가 메트릭을 가져올 수 있도록 어플리케이션이나 시스템을 모니터링하는 메트릭 변환기로 미리 메트릭을 만들어놓아 노출시킵니다.
- node-exporter : OS 레벨 메트릭 (CPU, 메모리, 디스크)
- kube-metric-exporter : Kubernetes 리소스 상태 정보
- cAdvisor : 컨테이너 메트릭 모니터링
- blackbox-exporter : 외부 HTTP/S 서비스 모니터링
4) AlertManager
Prometheus에서 알림을 관리하는 컴포넌트입니다.
5) PushGateway
Prometheus는 기본적으로 Pull 방식이지만, 단기 실행되는 작업 (ex, 배치 작업)의 데이터 저장하려면 Push 방식이 필요한데, 그런 경우에 사용합니다.
6) ServiceDiscovery
모니터링 해야할 타겟 서비스 대상을 자동으로 발견하고 스크래핑 대상으로 추가하는 기능입니다.
- 일반적인 물리 장비에 설치되는 prometheus 라면 exporter를 노출하여 직접 스크래핑하지만, 쿠버네티스에서는 동적으로 생성, 삭제되는 서비스가 많기 때문에 서비스 디스커버리가 필요
- Prometheus Operator를 사용하기 때문에 scrape_configs를 직접 설정할 필요 없이, ServiceMonitor 리소스 이용하여 라벨, 엔드포인트 매칭하는 서비스를 감시하여 설정이 반영
ServiceMonitor
특정 라벨 가진 쿠버네티스 서비스 대상 모니터링 (서비스 엔드포인트 통해 메트릭 수집)
- node-exporter
- kube-state-metrics
- kubelet
- api-server
- coredns
- kube-controller-manager
- kube-proxy
- 등등
PodMonitor
특정 라벨 가진 쿠버네티스 파드 대상 모니터링 (파드 메트릭 엔드포인트 통해 수집)
ServiceMonitor는 Service의 엔드포인트만 스크래핑하기 때문에 Pod가 여러 개일때 일부 Pod만 스크래핑할 수 있습니다.
PodMonitor는 각 Pod에 직접 접근해서 개별적으로 메트릭을 수집하기 때문에 모든 Pod의 데이터를 빠짐없이 수집할 수 있어서 HPA환경이나 수집해야하는 Pod 수가 많은 경우 Servicemonitor보다는 Podmonitor 수집이 필요합니다.
Istio 메트릭이 쿠버네티스 메트릭과 통합되는 이유
사내 환경에서 별 다른 설정을 하지 않았는데 어플리케이션 서비스에서 사용하는 Istio 메트릭도 같이 수집되고 있어서, 이유가 궁금해져서 작성하였습니다.
https://istio.io/latest/docs/ops/integrations/prometheus/#option-1-metrics-merging
Prometheus
How to integrate with Prometheus.
istio.io
Istio의 Envoy Proxy들은 metric을 프로메테우스 metric 형식으로 노출합니다. - Envoy Proxy의 메트릭은 Pod의 15090 포트로 노출
Istio는 기존 어플리케이션이 노출하는 프로메테우스 메트릭이 있다면 그걸 병합해서 merged prometheus telemtry의 포트인 15020에 덮어씁니다. 이렇게 두 메트릭을 병합하는 옵션은 Istio meshConfig.enablePrometheusMerge 옵션에 의해 설정되는데, 기본값이 true라서 Istio proxy가 주입되었다면 기존 어플리케이션의 메트릭이 병합됩니다.
Prometheus 메트릭 종류
1) Gauge
특정 시점 값을 표현하기 위해 사용하는 메트릭 타입
현재 상태 측정한 값으로 증가/감소 가능
ex)
- 메모리 사용량 (node_memory_Active_bytes)
- CPU 온도 (node_thermal_zone_temp)
- 현재 연결된 세션 수 (nginx_connections_active)
- 현재 큐(queue)에 남아 있는 작업 개수 (queue_length)
2) Counter
누적된 값을 표현하기 위해 사용하는 메트릭 타입, 증가 시 구간별로 변화 확인 가능
누적 값으로 항상 증가하는 값
ex)
- HTTP 요청 횟수 (http_requests_total)
- 프로세스 시작 이후 실행된 명령 개수 (process_cpu_seconds_total)
- 패킷 전송량 (node_network_transmit_bytes_total)
- 에러 발생 횟수 (nginx_http_requests_errors_total)
3) Summary
구간 내에 있는 메트릭 값의 빈도, 중앙값 등 통계적 메트릭
중앙값으로 백분위수 등 통계 기반 메트릭
ex)
- HTTP 응답 시간의 중앙값 (http_request_duration_seconds{quantile=”0.5”})
- 상위 99% 사용자 응답 시간 (http_request_duration_seconds{quantile=”0.99”})
4) Histogram
사전에 미리 정의한 구간 내에 있는 메트릭 값의 빈도 측정 (함수로 측정 포맷을 변경)
범위 기반 분포 저장
ex)
- HTTP 요청 응답 시간 분포 (http_request_duration_seconds_bucket)
- 디스크 I/O 속도 분포
- 응용 프로그램에서 처리하는 요청 크기 분포
Prometheus 연산자
- sum : 메트릭 합산
- count : 메트릭 갯수
- avg : 메트릭 평균
- stddev, stdvar : 표준편차, 표준 분산
- min, max : 최대 최소
- topk, bottomk : 메트릭 상위 하위 n번째
- count_values : 시계열에 대한 빈도 히스토그램
- without : 특정값을 제외한 메트릭 선택
- by : 메트릭 그룹화
Prometheus 데이터 저장 과정
프로메테우스는 데이터를 시계열 데이터(Series로 저장. 최근 데이터 는 WAL + mmap chunk에 저장되고, 일정 기간 지나면 Block단위로 압축해서 디스크에 저장되는 구조
- 인메모리 : WAL(Wrtie Ahead Logging)파일 & 인메모리 버퍼
- 로컬 파일 시스템 : 일반적인 chunk 블록 파일
Prometheus 기본 용어
metric data exporter가 prometheus에 노출한 데이터 Series metric data 이름 + 라벨 조합prometheus에 Series + 시계열값 (time, value) 으로 저장proemetheus 내부에서는 series 형태로 데이터 관리하고, 새로운 값이 들어올때마다 새로운 Series에 추가 Head Chunks - 2시간 이내 데이터 메모리에 저장 (메모리 + mmap 활용) WAL(Write Ahead Log) - 로그 데이터 유실을 방지하고 복구하기 위해, 새로운 Series 데이터를 먼저 기록하는 로그 파일데이터를 디스크에 바로 저장하지 않고 WAL로 기록 후 mmaap 데이터를 나중에 Block Chunk으로 변환, 그 이후 wal 삭제 데이터를 메모리에 저장하지만, 주기적으로 WAL 파일에 백업, 데이터를 인메모리와 WAL에 저장하고 있다가 데이터를 chunk 블록으로 flush 한뒤 가장 오래된 WAL 파일 삭제즉시즉시 기록하는 로그라 압축하지 않아서 데이터 크기 큼 M-map chunks : Memory Mapped Chunks - 현재 활성 데이터 최근 데이터를 메모리에 저장할 때 mmap (메모리 매핑) 사용해 빠르게 접근메모리 내에서는 압축된 chunk 형태로 데이터 유지Prometheus가 재시작 될 경우, mmap chunk가 날아갈 수 도 있기 때문에 WAL을 복구 (Reply)하는 과정이 필요 (2시간 이내 데이터) Block Chunks - 2시간 이상 데이터 디스크에 저장 Mmap Chunk 데이터를 Block chunk으로 변환해서 디스크에 저장Block 내부에는 여러 개의 chunk 포함
1) Series 생성
Prometheus가 특정 metric_name{label1=”value1”, label2=”value2”} 형태의 시계열 데이터를 수집합니다.
각 시계열 데이터는 Series라고 부릅니다.
2) WAL(Write-Ahead Log)에 저장
데이터는 WAL에 먼저 저장해서, 프로메테우스가 갑자기 종료되더라도 복구 가능합니다. (mmap chunk에 먼저 쓰지 않음)
WAL은 메모리에 저장되며, 이후 디스크에 주기적으로 기록합니다.
3) mmap chunk에 데이터 저장 (메모리 활용)
빠르게 쿼리할 수 있도록(2시간 동안 데이터 유지할 수 있도록) 최신 데이터를 메모리 매핑합니다.
4) Block chunk에 주기적인 데이터 압축(디스크 저장)
일정 시간 지나면 mmap chunk 데이터를 Block으로 변환하여 디스크에 저장합니다.
5) Compaction (데이터 압축)
Block이 여러개 쌓이면 오래된 Block을 합쳐서 Compaction 수행합니다.
EKS 컨트롤 플레인 로그
EKS에서 컨트롤 플레인에 대한 정보는 사용자에게 추상화되어있어서 알기 어렵습니다. EKS에서 컨트롤 플레인에 대한 로깅은 기본적으로 비활성화되어있는데, 이를 AWS Cloudwatch logs로 전송하여 Kubernetes API 서버 및 컨트롤 플레인 컴포넌트들의 로그를 활성화하도록 하겠습니다.

EKS에서 5가지 컨트롤 플레인에서 대한 로그를 제공합니다.
- api : Kubernetes API 서버의 요청 및 응답 로그
- audit : Kubenetes 감사(Audit) 로그
- authenticator : IAM 인증 관련 로그 (aws-iam-authenticator
- controllerManager : Kubernetes 컨트롤러 매니저 관련 로그
- scheduler : Kubernetes 스케줄러 관련 로그
기본적으론는 모두 꺼져있어 아래 작업처럼 수동으로 활성화 시켜줘야하며, 컨트롤 플레인 로깅을 활성화하면 CloudWatch Logs 사용량에 따라 요금이 발생할 수 있으므로, 필요 없는 로그는 비활성화하는 것이 좋습니다.
++ Amazone Cloudwatch란?
AWS 리소스 및 AWS에서 실행되는 어플리케이션을 실시간 모니터링이 가능하도록 지원하는 솔루션입니다.
Cloudwatch를 사용하여 리소스 및 어플리케이션에 대해 측정할 수 있느 변수인 지표를 수집하고 추적할 수 있습니다.
https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/WhatIsCloudWatch.html
Amazon CloudWatch란 무엇인가요? - Amazon CloudWatch
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
❯ aws eks update-cluster-config --region ap-northeast-2 --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
{
"update": {
"id": "e749911e-7774-3b90-a3ed-d4b151c8ddcb",
"status": "InProgress",
"type": "LoggingUpdate",
"params": [
{
"type": "ClusterLogging",
"value": "{\"clusterLogging\":[{\"types\":[\"api\",\"audit\",\"authenticator\",\"controllerManager\",\"scheduler\"],\"enabled\":true}]}"
}
],
"createdAt": "2025-03-02T00:47:59.197000+09:00",
"errors": []
}
}

로깅이 활성화되면 CloudWatch에서 해당 로그를 확인할 수 있습니다.
++) 로그 그룹이란?
AWS Cloudwatch Logs에서 로그 스트림을 저장하고 관리하는 단위입니다.
EKS에서 컨트롤 플레인 로깅을 활성화하면 로그 그룹이 자동으로 생성됩니다.
로그 그룹 (Log Group) # 여러 개의 로그 스트림 포함
├── 로그 스트림 (Log Stream) # 시간 순으로 저장된 로그 이벤트들의 모임
│ ├── 로그 이벤트 (Log Event) # 실제 개별적인 메시지 포함
│ ├── 로그 이벤트 (Log Event)
│ ├── ...
│
├── 로그 스트림 (Log Stream)
│ ├── 로그 이벤트 (Log Event)
│ ├── ...
│
├── 로그 스트림 (Log Stream)
│ ├── 로그 이벤트 (Log Event)
│ ├── ...
❯ aws logs describe-log-groups | jq
{
"logGroups": [
{
"logGroupName": "/aws/eks/eks-console-automode/cluster",
"creationTime": 1738998815962,
"metricFilterCount": 0,
"arn": "arn:aws:logs:ap-northeast-2:xxx:log-group:/aws/eks/eks-console-automode/cluster:*",
"storedBytes": 16658665,
"logGroupClass": "STANDARD",
"logGroupArn": "arn:aws:logs:ap-northeast-2:xxx:log-group:/aws/eks/eks-console-automode/cluster"
},
{
"logGroupName": "/aws/eks/myeks/cluster",
"creationTime": 1740844090723,
"metricFilterCount": 0,
"arn": "arn:aws:logs:ap-northeast-2:xxx:log-group:/aws/eks/myeks/cluster:*",
"storedBytes": 0,
"logGroupClass": "STANDARD",
"logGroupArn": "arn:aws:logs:ap-northeast-2:xxx:log-group:/aws/eks/myeks/cluster"
}
]
}
로그를 확인해보겠습니다.
# follow 옵션을 주면 실시간 로그를 바로 출력할 수 있습니다.
❯ aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
2025-03-01T15:48:11.801000+00:00 kube-apiserver-audit-bf7fa45ae808536e5c93358852add1a1 {"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"1e533d1a-22ec-4ea6-be25-e8d61729c167","stage":"ResponseComplete","requestURI":"/apis/coordination.k8s.io/v1/namespaces/kube-system/leases/eks-coredns-autoscaler","verb":"get","user":{"username":"eks:coredns-autoscaler","groups":["system:authenticated"]},"sourceIPs":["10.0.180.168"],"userAgent":"controller/v0.0.0 (linux/amd64) kubernetes/$Format/leader-election","objectRef":{"resource":"leases","namespace":"kube-system","name":"eks-coredns-autoscaler","apiGroup":"coordination.k8s.io","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2025-03-01T09:34:31.582714Z","stageTimestamp":"2025-03-01T09:34:31.587464Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by RoleBinding \"eks:coredns-autoscaler/kube-system\" of Role \"eks:coredns-autoscaler\" to User \"eks:coredns-autoscaler\""}}
2025-03-01T15:48:11.801000+00:00 kube-apiserver-audit-bf7fa45ae808536e5c93358852add1a1 {"kind":"Event","apiVersion":"audit.k8s.io/v1","level":"Metadata","auditID":"99780557-8244-477c-9ed4-373eb3c94726","stage":"ResponseComplete","requestURI":"/apis/coordination.k8s.io/v1/namespaces/kube-system/leases/kube-controller-manager?timeout=5s","verb":"get","user":{"username":"system:kube-controller-manager","groups":["system:authenticated"]},"sourceIPs":["10.0.180.168"],"userAgent":"kube-controller-manager/v1.31.6 (linux/amd64) kubernetes/7555883/leader-election","objectRef":{"resource":"leases","namespace":"kube-system","name":"kube-controller-manager","apiGroup":"coordination.k8s.io","apiVersion":"v1"},"responseStatus":{"metadata":{},"code":200},"requestReceivedTimestamp":"2025-03-01T09:34:31.794155Z","stageTimestamp":"2025-03-01T09:34:31.798149Z","annotations":{"authorization.k8s.io/decision":"allow","authorization.k8s.io/reason":"RBAC: allowed by ClusterRoleBinding \"system:kube-controller-manager\" of ClusterRole \"system:kube-controller-manager\" to User \"system:kube-controller-manager\""}}
...
EKS 콘솔에서 api 서버 로그 보기를 클릭하니 Cloudwatch 콘솔로 접속되었습니다.
왼쪽 탭에서 Logs Insights라는 로그를 대화식으로 검색하고 분석할 수 있는 기능을 활용하여 쿼리를 사용하여 로그를 확인해보겠습니다.


로깅을 종료하겠습니다.
❯ eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region ap-northeast-2 --disable-types all --approve
❯ aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster
EKS 데이터 플레인 로그
EKS에서 컨트롤 플레인 로깅은 직접 수집해야합니다.
데이터 플레인 로그 수집 방법에는 여러 가지가 있지만, 일반적으로 Fluent Bit, Fluentd, Opentelemetry Collector, Promtail이 있습니다.
(AWS 공식문서에는 Fluent Bit를 활용한 로깅에 대해 소개하였습니다.)
https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/Container-Insights-setup-logs-FluentBit.html#Container-Insights-FluentBit-setup
Fluent Bit를 DaemonSet로 설정하여 CloudWatch Logs에 로그 전송 - Amazon CloudWatch
Container Insights에 이미 FluentD가 구성되어 있고 FluentD DaemonSet가 예상대로 실행되지 않는 경우(containerd 런타임을 사용하는 경우 발생할 수 있음), Fluent Bit를 설치하기 전에 Fluent Bit를 제거해야 Fluent
docs.aws.amazon.com
AWS에서 제공하는 방식으로 Fluent Bit를 이용하여 EKS 파드의 로그를 수집해보도록 하겠습니다.
이때, Fluent Bit는 컨테이너를 데몬셋으로 동작시키고, 데이터 플레인의 3가지 로그를 CloudWatch Logs에 전송합니다.

- 각 컨테이너/파드 로그 (/var/log/containers),
- 노드(호스트) 로그 (/var/log/dmesg, /var/log/secure, /var/log/messages)
- 쿠버네티스 데이터플레인 로그 (/var/log/journal <- kubelet.service, kubeproxy.service, docker.service)
이 때 로그는 Fluent Bit만으로도 충분한데 왜 Cloudwatch agent까지 설치할까요?
Fluent Bit만 사용하면 Cloud Watch Logs에서 원본 로그만 저장할 수 있지만, Cloudwatch Container insights를 활성화하면, 메트릭과 로그를 통합하여 분석이 가능하기 때문입니다.
Cloudwatch에 EKS 클러스터 대시보드가 생성되어 클러스터, 노드, 파드의 CPU, Memory 등 메트릭 값이 시각화되고, 로그와 메트릭을 통합하여 분석할 수 있습니다.
++ Amazone Cloudwatch Container Insight
컨테이너형 어플리케이션 및 마이크로 서비스에 대한 모니터링, 트러블 슈팅 및 알람을 위한 관리형 솔루션입니다.
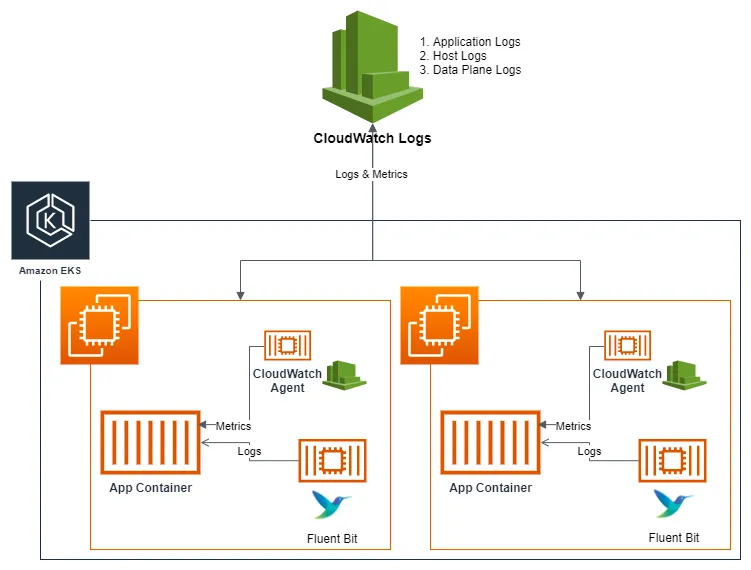
Fluent Bit이 로그를 수집하는 방법
Fluent Bit은 노드에 모두 하나씩 뜨는 Daemonset으로 배포됩니다.
이때 Kubernetes의 로그 파일을 직접 읽어와서 수집하는 방식으로, tail이나 systemd 플러그인을 사용하여 로그를 가져옵니다.
1) 파드 로그 수집 (tail 플러그인)
- /var/log/containers/*.log 경로에서 컨테이너 표준 출력 로그 수집
- Kubernetes 메타데이터(파드명, 네임스페이스 등) 추가 후 전송
노드 로그 수집 (systemd 플러그인)
- /var/log/journal/ 경로에서 kubelet, docker, containerd 서비스 로그 수집
로그 필터링 및 전송 (kubernetes 필터, cloudwatch_logs 출력 플러그인)
- 필터 적용 후 CloudWatch 등으로 전송
일부 Fluent Bit 설정에서는 docker.sock을 마운트하여 컨테이너 정보를 수집하는데, docker.sock은 호스트의 Docker 데몬과 직접 통신할 수 있는 Unix 소켓으로 만약 악의적인 사용자가 Fluent Bit 컨테이너에서 docker 명령어를 실행할 수 있다면, 호스트 파일 시스템을 마운트하고 Root 권한을 획득 가능하여 컨테이너 탈출(Container Escape)이 가능해지며, 노드 전체가 공격에 노출될 위험이 있습니다.
우선, Fluent Bit만 설치해본 후, 로그를 확인한 뒤 CloudWatch agent를 설치하여 CloudWatch Container Insights까지 비교하며 확인
❯ kubectl apply -f https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/cloudwatch-namespace.yaml
namespace/amazon-cloudwatch created
❯ ClusterName=myeks
❯ RegionName=ap-northeast-2
❯ FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
[[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On'
[[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On'
kubectl create configmap fluent-bit-cluster-info \
--from-literal=cluster.name=${ClusterName} \
--from-literal=http.server=${FluentBitHttpServer} \
--from-literal=http.port=${FluentBitHttpPort} \
--from-literal=read.head=${FluentBitReadFromHead} \
--from-literal=read.tail=${FluentBitReadFromTail} \
--from-literal=logs.region=${RegionName} -n amazon-cloudwatch
❯ kubectl apply -f https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/fluent-bit/fluent-bit.yaml
serviceaccount/fluent-bit created
clusterrole.rbac.authorization.k8s.io/fluent-bit-role created
clusterrolebinding.rbac.authorization.k8s.io/fluent-bit-role-binding created
configmap/fluent-bit-config created
daemonset.apps/fluent-bit created
# fluent-bit 설정파일 일부
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: amazon-cloudwatch
labels:
k8s-app: fluent-bit
data:
fluent-bit.conf: |
[SERVICE]
Flush 5
Grace 30
Log_Level error
Daemon off
Parsers_File parsers.conf
HTTP_Server ${HTTP_SERVER}
HTTP_Listen 0.0.0.0
HTTP_Port ${HTTP_PORT}
storage.path /var/fluent-bit/state/flb-storage/
storage.sync normal
storage.checksum off
storage.backlog.mem_limit 5M
@INCLUDE application-log.conf
@INCLUDE dataplane-log.conf
@INCLUDE host-log.conf
application-log.conf: |
[INPUT]
Name tail
Tag application.*
Exclude_Path /var/log/containers/cloudwatch-agent*, /var/log/containers/fluent-bit*, /var/log/containers/aws-node*, /var/log/containers/kube-proxy*, /var/log/containers/fluentd*
Path /var/log/containers/*.log
multiline.parser docker, cri
DB /var/fluent-bit/state/flb_container.db
Mem_Buf_Limit 50MB
Skip_Long_Lines On
Refresh_Interval 10
Rotate_Wait 30
storage.type filesystem
Read_from_Head ${READ_FROM_HEAD}
[INPUT]
Name tail
Tag application.*
Path /var/log/containers/fluent-bit*
multiline.parser docker, cri
DB /var/fluent-bit/state/flb_log.db
Mem_Buf_Limit 5MB
Skip_Long_Lines On
Refresh_Interval 10
Read_from_Head ${READ_FROM_HEAD}
앗차차 권한이 없어서 다음 에러가 발생합니다.
# Fluent Bit 에러 로그
CreateLogStream API responded with error='AccessDeniedException'
Failed to create log stream
Failed to send events
# CloudWatch로 로그 전송 권한이 포함된 IAM Role 생성
❯ eksctl create iamserviceaccount \
--name fluent-bit \
--namespace amazon-cloudwatch \
--cluster $CLUSTER_NAME \
--role-name $CLUSTER_NAME-fluent-bit-role \
--attach-policy-arn arn:aws:iam::aws:policy/CloudWatchAgentServerPolicy \
--role-only \
--approve
❯ kubectl annotate serviceaccount fluent-bit \
-n amazon-cloudwatch \
eks.amazonaws.com/role-arn=arn:aws:iam::941377114730:role/$CLUSTER_NAME-fluent-bit-role \
--overwrite
serviceaccount/fluent-bit annotated
# fluent-bit daemonset 재시작